How fetch data from HBase
Step 1: Instantiate the Configuration Class. … Step 2: Instantiate the HTable Class. … Step 3: Instantiate the Get Class. … Step 4: Read the Data. … Step 5: Get the Result. … Step 6: Reading Values from the Result Instance.
How do I transfer data from HBase?
- Stop sending writes to your HBase cluster.
- Take snapshots of the HBase cluster’s tables.
- Export the snapshot files to Cloud Storage.
- Compute hashes and export them to Cloud Storage.
- Create destination tables in Bigtable.
- Import the HBase data from Cloud Storage into Bigtable.
How do I export data from HBase to CSV?
2 Answers. Creating an external Hive table mapped on to HBase table using HBaseStorageHandler can solve your problem ,you can now use “select * from table_name” to get data into a csv table (stored as textfile fields terminted by ‘,’).
How do I query a HBase table?
- Connect the data source to Drill using the HBase storage plugin. …
- Determine the encoding of the HBase data you want to query. …
- Based on the encoding type of the data, use the “CONVERT_TO and CONVERT_FROM data types” to convert HBase binary representations to an SQL type as you query the data.
What is the difference between GET and scan in HBase?
When you compare a partial key scan and a get, remember that the row key you use for Get can be a much longer string than the partial key you use for the scan. In that case, for the Get, HBase has to do a deterministic lookup to ascertain the exact location of the row key that it needs to match and fetch it.
How do I copy a HBase table from one cluster to another?
- Gather the current table splits on Cluster A. Before importing, we will need to create the table on Cluster B. …
- Create the table on Cluster B via the HBase shell. The HBase command line utility is the simplest way to do create an HBase table. …
- Use the CopyTable utility to copy the table from Cluster A to Cluster B.
What is HBase scan?
The HBase scan command scans entire table and displays the table contents. You can execute HBase scan command with various other options or attributes such as TIMERANGE, FILTER, TIMESTAMP, LIMIT, MAXLENGTH, COLUMNS, CACHE, STARTROW and STOPROW.
Does HBase support SQL query?
HBase is a column-oriented non-relational database management system that runs on top of Hadoop Distributed File System (HDFS). … Unlike relational database systems, HBase does not support a structured query language like SQL; in fact, HBase isn’t a relational data store at all.Can HBase work on S3?
Enabling HBase on Amazon S3 You can enable HBase on Amazon S3 using the Amazon EMR console, the AWS CLI, or the Amazon EMR API. The configuration is an option during cluster creation.
What is block cache in HBase?HBase BlockCache and its implementations. There is a single BlockCache instance in a region server, which means all data from all regions hosted by that server share the same cache pool (5). The BlockCache is instantiated at region server startup and is retained for the entire lifetime of the process.
Article first time published onHow do I know if HBase is running?
- Use the jps command to ensure that HBase is not running.
- Kill HMaster, HRegionServer, and HQuorumPeer processes, if they are running.
- Start the cluster by running the start-hbase.sh command on node-1.
What part of the data does HBase need to read when reading data?
META Table is one of the major components of HBase Operations. HBase Read operation needs to know which HRegion server has to be accessed for reading actual data, so, we use META Table in Read operation of HBase.
What is Phoenix Database?
Apache Phoenix is an open source, massively parallel, relational database engine supporting OLTP for Hadoop using Apache HBase as its backing store.
How do I query HBase table using Hive?
To access HBase data from Hive You can then reference inputTable in Hive statements to query and modify data stored in the HBase cluster. set hbase. zookeeper. quorum=ec2-107-21-163-157.compute-1.amazonaws.com; create external table inputTable (key string, value string) stored by ‘org.
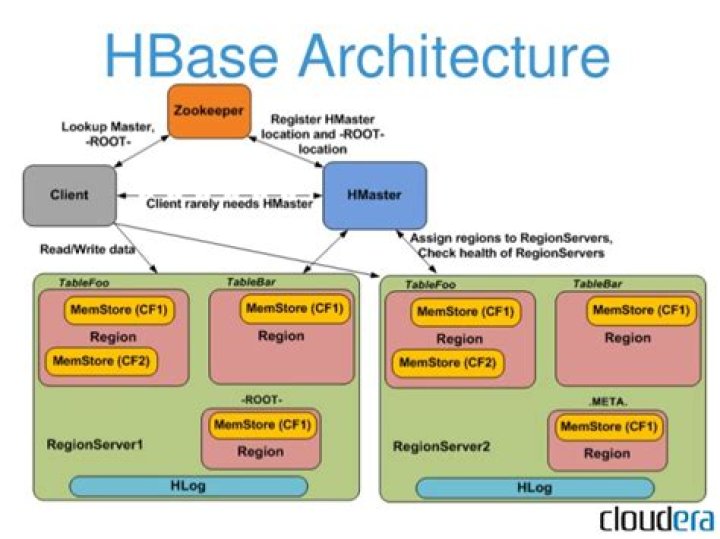
What are components of HBase?
HBase has three major components: the client library, a master server, and region servers.
How do I improve HBase performance scan?
- Decrease ZooKeeper timeout.
- Increase handlers.
- Increase heap settings.
- Enable data compression.
- Increase region size.
- Adjust block cache size.
- Adjust memstore limits.
- Increase blocking store files.
How do I clone a Hbase table?
- Step1: Create Snapshot of HBase table. …
- Step2: Clone Snapshot to new Namespace with same or different table names. …
- Step3: Use Scan Command to Verify Table in New namespace. …
- Step4: Delete Snapshot. …
- Step5: Drop Original Table.
How do I export a table from Hbase?
- Export $ bin/hbase org.apache.hadoop.hbase.mapreduce.Export \ <tablename> <outputdir> [<versions> [<starttime> [<endtime>]]]
- Copy the output directory in hdfs from the source to destination cluster.
- Import $ bin/hbase org.apache.hadoop.hbase.mapreduce.Import <tablename> <inputdir>
What is the main difference between HBase and DynamoDB?
Apache HBase gives you the option to have very flexible row key data types, whereas DynamoDB only allows scalar types for the primary key attributes. DynamoDB on the other hand provides very easy creation and maintenance of secondary indexes, something that you have to do manually in Apache HBase.
When do you use HBase vs Cassandra?
HBase is a NoSQL, distributed database model that is included in the Apache Hadoop Project. … HBase is designed for data lake use cases and is not typically used for web and mobile applications. Cassandra, by contrast, offers the availability and performance necessary for developing always-on applications.
What is Athena query?
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. … This makes it easy for anyone with SQL skills to quickly analyze large-scale datasets.
Is HBase NoSQL database?
The rise of growing data gave us the NoSQL databases and HBase is one of the NoSQL database built on top of Hadoop. This paper illustrates the HBase database its structure, use cases and challenges for HBase. HBase is suitable for the applications which require a real-time read/write access to huge datasets.
Who owns HBase?
HBase is an open-source non-relational distributed database modeled after Google’s Bigtable and written in Java. It is developed as part of Apache Software Foundation’s Apache Hadoop project and runs on top of HDFS (Hadoop Distributed File System) or Alluxio, providing Bigtable-like capabilities for Hadoop.
Why HBase is fast?
By storing data in rows of column families, HBase achieves a four dimensional data model that makes lookups exceptionally fast. … This is largely because the row keys uniqueness determine the data’s distribution across HDFS. HBase relies on Zookeeper for the coordination of cluster nodes.
Why HBase is NoSQL?
Apache HBase is a NoSQL key/value store which runs on top of HDFS. Unlike Hive, HBase operations run in real-time on its database rather than MapReduce jobs. HBase is partitioned to tables, and tables are further split into column families. … HBase works by storing data as key/value.
What is Bloom filter in HBase?
An HBase Bloom Filter is an efficient mechanism to test whether a StoreFile contains a specific row or row-col cell. Without Bloom Filter, the only way to decide if a row key is contained in a StoreFile is to check the StoreFile’s block index, which stores the start row key of each block in the StoreFile.
When does the rolling of Wal file occur?
As WALs grow, they are eventually closed and a new, active WAL file is created to accept additional edits. This is called “rolling” the WAL file. Once a WAL file is rolled, no additional changes are made to the old file. By default, WAL file is rolled when its size is about 95% of the HDFS block size.
Can HBase run without Hadoop?
HBase can be used without Hadoop. Running HBase in standalone mode will use the local file system. … The reason arbitrary databases cannot be run on Hadoop is because HDFS is an append-only file system, and not POSIX compliant. Most SQL databases require the ability to seek and modify existing files.
Does HBase need zookeeper?
HBase relies completely on Zookeeper. HBase provides you the option to use its built-in Zookeeper which will get started whenever you start HBAse.
How do I access HBase UI?
With the proxy set and the SSH connection open, you can view the HBase UI by opening a browser window with http:// master-public-dns-name :16010/master-status, where master-public-dns-name is the public DNS address of the cluster’s master node.
How does HBase store data internally?
HBase Architecture Just like in a Relational Database, data in HBase is stored in Tables and these Tables are stored in Regions. When a Table becomes too big, the Table is partitioned into multiple Regions. These Regions are assigned to Region Servers across the cluster.