What is bucketing in spark
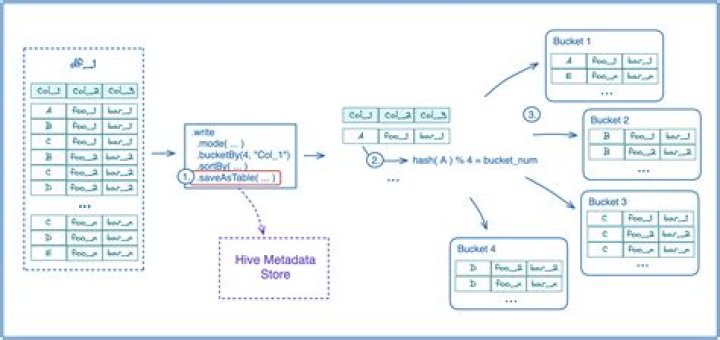
Bucketing is an optimization technique in Spark SQL that uses buckets and bucketing columns to determine data partitioning. When applied properly bucketing can lead to join optimizations by avoiding shuffles (aka exchanges) of tables participating in the join.
What is difference between bucketing and partitioning?
Bucketing decomposes data into more manageable or equal parts. With partitioning, there is a possibility that you can create multiple small partitions based on column values. If you go for bucketing, you are restricting number of buckets to store the data. This number is defined during table creation scripts.
What is difference between partitioning and bucketing in Hive?
Hive Partition is a way to organize large tables into smaller logical tables based on values of columns; one logical table (partition) for each distinct value. … Hive Bucketing a.k.a (Clustering) is a technique to split the data into more manageable files, (By specifying the number of buckets to create).
What is the meaning bucketing?
Bucketing is an unethical practice whereby a broker generates a profit by misleading their client about the execution of a particular trade. … A brokerage firm that engages in unscrupulous activities, such as bucketing, is often referred to as a bucket shop.What is bucketing of data?
Data binning, also called discrete binning or bucketing, is a data pre-processing technique used to reduce the effects of minor observation errors. … Statistical data binning is a way to group numbers of more or less continuous values into a smaller number of “bins”.
What is bucketing and where it is used?
The bucketing in Hive is a data organizing technique. It is similar to partitioning in Hive with an added functionality that it divides large datasets into more manageable parts known as buckets. So, we can use bucketing in Hive when the implementation of partitioning becomes difficult.
What is bucketing in Hive?
Bucketing in hive is the concept of breaking data down into ranges, which are known as buckets, to give extra structure to the data so it may be used for more efficient queries. The range for a bucket is determined by the hash value of one or more columns in the dataset (or Hive metastore table).
What is the example of bucket?
The definition of a bucket is a round and deep container used for carrying things. An example of a bucket is what you’d use to carry water from a faucet to a kiddie pool. To ride (a horse) long and hard.What is bucketing in SQL?
Bucketing, also known as binning, is useful to find groupings in continuous data (particularly numbers and time stamps). While it’s often used to generate histograms, bucketing can also be used to group rows by business-defined rules.
What is the benefit of bucketing in Hive?With bucketing in Hive, you can decompose a table data set into smaller parts, making them easier to handle. Bucketing allows you to group similar data types and write them to one single file, which enhances your performance while joining tables or reading data.
Article first time published onHow does bucketing help in the faster execution of queries?
It provides faster query response like portioning. In bucketing due to equal volumes of data in each partition, joins at Map side will be quicker.
Can we use bucketing without partitioning?
Along with Partitioning on Hive tables bucketing can be done and even without partitioning. vi. Moreover, Bucketed tables will create almost equally distributed data file parts.
What is quantile bucketing?
Quantile Bucketing How might we improve this situation? Figure 3: Number of cars sold at different prices. … The solution lies in creating buckets that each have the same number of points. This technique is called quantile bucketing. For example, the following figure divides car prices into quantile buckets.
How does hive choose a bucketing?
What are the factors to be considered while deciding the number of buckets? One factor could be the block size itself as each bucket is a separate file in HDFS. The file size should be at least the same as the block size. The other factor could be the volume of data.
How can you enable bucketing in hive?
The command set hive. enforce. bucketing = true; allows the correct number of reducers and the cluster by column to be automatically selected based on the table. Otherwise, you would need to set the number of reducers to be the same as the number of buckets as in set mapred.
Can we do partitioning and bucketing on same column?
To conclude, you can partition and use bucketing for storing results of the same CTAS query. These techniques for writing data do not exclude each other. Typically, the columns you use for bucketing differ from those you use for partitioning. … You can store its data in more than one bucket in Amazon S3.
Why is a bucket called a bucket?
“pail or open vessel for drawing and carrying water and other liquids,” mid-13c., from Anglo-French buquet “bucket, pail,” from Old French buquet “bucket,” which is from Frankish or some other Germanic source, or a diminutive of cognate Old English buc “pitcher, bulging vessel,” originally “belly” (buckets were …
What are buckets made of?
Many buckets are made out of high-density polyethylene. HDPE is a durable, non-reactive thermoplastic that resists impact and inhospitable climates during transit or storage. In the blow molding process, raw HDPE resin, which in the beginning of the molding process is called stock, is loaded into a hopper.
What is bucketing in Athena?
Bucketing puts the same values of a column in the same file(s). So if you bucket by id, then all the rows for id = 1 are in the same file. This happens after partitioning. Bucketing helps performance in some cases of Joins, Aggregates, and filters by reducing files to read.
What are partitions in spark?
In spark, the partition is an atomic chunk of data. Simply putting, it is a logical division of data stored on a node over the cluster. In apache spark, partitions are basic units of parallelism and RDDs, in spark are the collection of partitions.
What is sort merge join in spark?
Sort-Merge join is composed of 2 steps. The first step is to sort the datasets and the second operation is to merge the sorted data in the partition by iterating over the elements and according to the join key join the rows having the same value. From spark 2.3 Merge-Sort join is the default join algorithm in spark.
What is bucket in PE?
The teacher dumps the pieces of paper out into the circle in the middle of the gym (circle or several hoops). The students will then begin playing “Buckets” after the teacher has dumped the paper. The students must run, skip, gallop, crawl, under control, to the paper.
What is bucket AWS?
A bucket is a container for objects. An object is a file and any metadata that describes that file. To store an object in Amazon S3, you create a bucket and then upload the object to the bucket. When the object is in the bucket, you can open it, download it, and move it. … With Amazon S3, you pay only for what you use.
What is crane bucket?
The bucket could be attached to the lifting hook of a crane, at the end of the arm of an excavating machine, to the wires of a dragline excavator, to the arms of a power shovel or a tractor equipped with a backhoe loader or to a loader, or to a dredge. …
Why do we partition data?
Partitioning can improve scalability, reduce contention, and optimize performance. It can also provide a mechanism for dividing data by usage pattern. For example, you can archive older data in cheaper data storage.
What is SerDe in hive?
SerDe is short for Serializer/Deserializer. Hive uses the SerDe interface for IO. The interface handles both serialization and deserialization and also interpreting the results of serialization as individual fields for processing.
Can we have bucketing for external tables?
Yes, Hive does support bucketing and partitioning for external tables.
How is quantile calculated in pandas?
The quantile() function is used to get values at the given quantile over requested axis. Value between 0 <= q <= 1, the quantile(s) to compute. Equals 0 or ‘index’ for row-wise, 1 or ‘columns’ for column-wise. If False, the quantile of datetime and timedelta data will be computed as well.
What is histogram quantile?
The histogram_quantile operator calculates the φ-quantile (0 ≤ φ ≤ 1) from the buckets of a Prometheus histogram. The histogram_quantile operator calculates the φ-quantile (0 ≤ φ ≤ 1) from the buckets of a histogram. … It is equivalent to the PromQL histogram_quantile() operator.
What is the 25th percentile?
25th Percentile – Also known as the first, or lower, quartile. The 25th percentile is the value at which 25% of the answers lie below that value, and 75% of the answers lie above that value. 50th Percentile – Also known as the Median. … Half of the answers lie below the median and half lie above the median.
Can we do bucketing on string column?
1 Answer. Yes you need to cluster your data based on country. and you need to define the number of buckets based on the total number of countries.