Where do AWS Glue jobs run
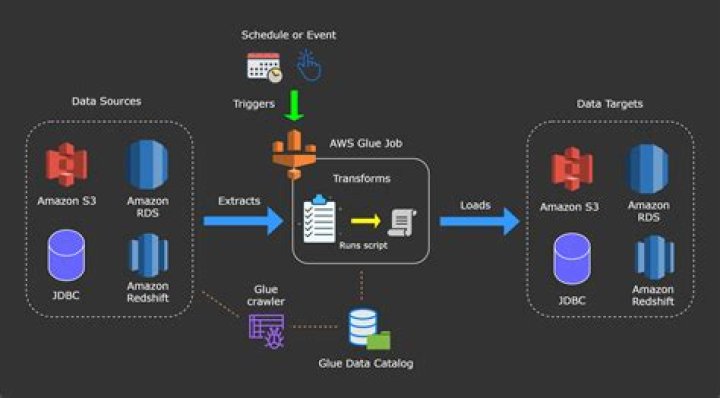
AWS Glue runs your ETL jobs in an Apache Spark serverless environment. AWS Glue runs these jobs on virtual resources that it provisions and manages in its own service account.
How do you make glue jobs?
- Create a Python script file (or PySpark)
- Copy it to Amazon S3.
- Give the Amazon Glue user access to that S3 bucket.
- Run the job in AWS Glue.
- Inspect the logs in Amazon CloudWatch.
How do I get job status glue?
You can view the status of an AWS Glue extract, transform, and load (ETL) job while it is running or after it has stopped. You can view the status using the AWS Glue console, the AWS Command Line Interface (AWS CLI), or the GetJobRun action in the AWS Glue API.
What is job in AWS Glue?
A job is the business logic that performs the extract, transform, and load (ETL) work in AWS Glue. When you start a job, AWS Glue runs a script that extracts data from sources, transforms the data, and loads it into targets. You can create jobs in the ETL section of the AWS Glue console.How do I migrate jobs from glue?
Actions to migrate to AWS Glue 3.0 For existing jobs, change the Glue version from the previous version to Glue 3.0 in the job configuration. In the console, choose Spark 3.1, Python 3 (Glue Version 3.0) or Spark 3.1, Scala 2 (Glue Version 3.0) in Glue version .
How do I get a job with AWS?
To create a new job definition Open the AWS Batch console at . From the navigation bar, select the Region to use. In the navigation pane, choose Job definitions, Create. For Name, enter a unique name for your job definition.
Why does AWS Glue take so long?
The reason it takes a long time is that GLUE builds an environment when you run the first job (which stays alive for 1 hours) if you run the same script twice or any other script within one hour, the next job will take significantly less time.
What is maximum capacity in AWS Glue job?
The maximum number of workers you can define is 299 for G.1X , and 149 for G. 2X . For AWS Glue version 1.0 or earlier jobs, using the standard worker type, you must specify the maximum number of AWS Glue data processing units (DPUs) that can be allocated when this job runs.What is AWS Glue job bookmark?
AWS Glue tracks data that has already been processed during a previous run of an ETL job by persisting state information from the job run. This persisted state information is called a job bookmark. Job bookmarks help AWS Glue maintain state information and prevent the reprocessing of old data.
How do I create an ETL job in AWS Glue?- Editing ETL jobs in AWS Glue Studio.
- Getting started with notebooks in AWS Glue Studio.
- Adding connectors to AWS Glue Studio.
- View the job script.
- Modify the job properties.
- Save the job.
- Start a job run.
- View information for recent job runs.
How do you stop AWS Glue job?
To stop a workflow run (console) Open the AWS Glue console at /glue/ . In the navigation pane, under ETL, choose Workflows. Choose a running workflow, and then choose the History tab. Choose the workflow run, and then choose Stop run.
What is Max concurrency in glue job?
It means that you can run up to three of the same glue jobs in parallel and these tasks cannot exceed the limit of 100 DPU’s in total.
How do I check my glue job status from Lambda?
To test the Lambda function and CloudWatch Events rule, run your AWS Glue crawler. Then, check the History tab of your AWS Glue ETL job. The Run status should display Starting or Running.
Is APIs are glue?
Integrating existing services to their applications through APIs has allowed developers to build increasingly complex and capable applications, which has led to the rise of giant Web services and mobile applications. Because of this, APIs are often referred to as the glue that holds the digital world together.
How do I rename AWS Glue job?
- You can use S3’s mv operation to rename the files. …
- That would make up for even more of a workaround – i would have to create lambda, that fetches data from s3 tmp names job bucket, and then changes names in the other bucket.
How does AWS Glue crawler work?
A crawler can crawl multiple data stores in a single run. … Upon completion, the crawler creates or updates one or more tables in your Data Catalog. Extract, transform, and load (ETL) jobs that you define in AWS Glue use these Data Catalog tables as sources and targets.
How can glue improve job performance?
Push down predicates: Glue jobs allow the use of push down predicates to prune the unnecessary partitions from the table before the underlying data is read. This is useful when you have a large number of partitions in a table and you only want to process a subset of them in your Glue ETL job.
How long does a glue job take?
It can take up to 20 minutes to start up a Glue job (but can take a little less time if you had run it recently) and that is not counting the time it takes to actually run the job. Compare that to the startup time of GCP’s Dataproc which typically takes around 60–90 seconds.
How does AWS Glue charge?
You are charged an hourly rate based on the number of Data Processing Units (or DPUs) used to run your ETL job. … By default, AWS Glue allocates 10 DPUs to each Apache Spark job. You are billed $0.44 per DPU-hour in increments of 1 second, rounded up to the nearest second.
Can you get an AWS job with no experience?
Can you learn AWS without experience? Yes. It’s possible to learn AWS and get certified without an IT background or degree, provided the necessary training hours are completed. The most approachable AWS exams are the “cloud practitioner” or the “associate” exams.
Does fresher get job on AWS?
Yes, freshers with Associate AWS Certified Solutions Architect can apply for this job role. If you dont have the certification then you must be really good with the domain knowledge.
Does Amazon Web Services pay well?
While ZipRecruiter is seeing annual salaries as high as $211,000 and as low as $24,000, the majority of salaries within the Amazon Web Services jobs category currently range between $70,000 (25th percentile) to $160,500 (75th percentile) with top earners (90th percentile) making $206,000 annually across the United …
What is Job commit in glue?
The method job. commit() can be called multiple times and it would not throw any error as well. However, if job. commit() would be called multiple times in a Glue script then job bookmark will be updated only once in a single job run that would be after the first time when job.
What is dynamic frame in AWS Glue?
A DynamicFrame is similar to a DataFrame , except that each record is self-describing, so no schema is required initially. Instead, AWS Glue computes a schema on-the-fly when required, and explicitly encodes schema inconsistencies using a choice (or union) type.
How do I use an external Python library in AWS Glue job?
- Open the AWS Glue console.
- In the navigation pane, Choose Jobs.
- Select the job where you want to add the Python module.
- Choose Actions, and then choose Edit job.
- Expand the Security configuration, script libraries, and job parameters (optional) section.
- Choose Save.
Which programming language is supported for ETL jobs in AWS Glue?
AWS Glue ETL scripts can be coded in Python or Scala. Python scripts use a language that is an extension of the PySpark Python dialect for extract, transform, and load (ETL) jobs.
Which engine is supported by AWS Glue?
AWS Glue enables you to perform ETL operations on streaming data using continuously-running jobs. AWS Glue streaming ETL is built on the Apache Spark Structured Streaming engine, and can ingest streams from Amazon Kinesis Data Streams, Apache Kafka, and Amazon Managed Streaming for Apache Kafka (Amazon MSK).
How do you increase DPU in AWS Glue?
Right now there is no way to configure DPU memory, but you can request a limit increase on your account to be able to use more DPUs. As of April 2019, there are two new types of workers: You can now specify a worker type for Apache Spark jobs in AWS Glue for memory intensive workloads.
Can AWS Glue be triggered by S3?
You can do this using an AWS Lambda function invoked by an Amazon S3 trigger to start an AWS Glue crawler that catalogs the data. … The AWS Glue ETL job converts the data to Apache Parquet format and stores it in the processed S3 bucket.
Can Lambda trigger a glue job?
4 Answers. Lambda will kick of the glue trigger and exit. The Glue job will keep on running.
How do you trigger lambda function from glue job?
- Click on ‘Rules’ from the left menu.
- For ‘Event Source’, choose ‘Event Pattern’ and in ‘Service Name’ choose ‘Glue’
- For ‘Event Type’ choose ‘Glue Job State Change’
- On the right side of the page, in the ‘Targets’ section, click ‘Add Target’ -> ‘Lambda Function’ and then choose your function.